<font color=Cyan>一、HADOOP简介</font>
<font color=DarkGoldenRod>1、为什么需要Hadoop?</font>
从一个例子开始,现在我们业务系统通过nginx转发tomcat,所有用户都通过访问Nginx访问我们的功能,Nginx为我们记录了accessLog,我们可以分析这些日志来挖掘一些用户行为。为网站运营提供统计支持。
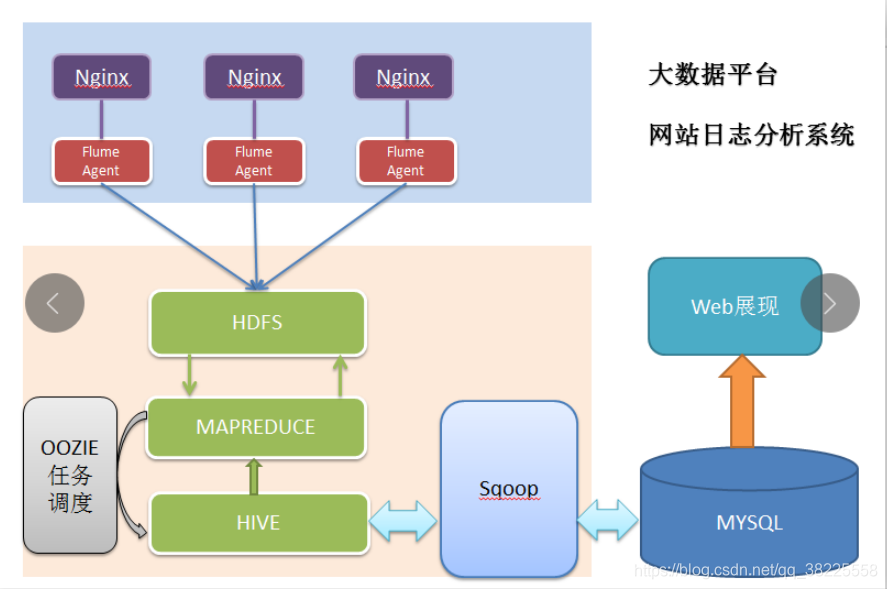
Flume Agent:做日志收集 HDFS:类似于fastDFS一样的文件管理系统(这里是存储上面收集的日志信息) MAPREDUCE:通过代码去分析HDFS中的日志数据信息 HIVE:通过命令去分析 (和MAPREDUCE一样作为计算框架) Sqoop:将数据迁移到MySQL中 最后可在Web端做Highcharts图表显示信息
要想分析出数据必须解决以下问题:
-
海量日志存储 hdfs
-
从海量日志中提取有效信息 mapreduce
-
想操作mysql数据库一样查询这些数据 hive
-
查询通过期望把数据导出到mysql,供页面展示
其实我们可以使用hadoop来完成以上操作。下面我们就来聊一下hadoop的一些概念…
<font color=DarkGoldenRod>2、什么是Hadoop?</font>
狭义: Hadoop是apache旗下的一套开源软件平台
Hadoop提供的功能:利用服务器集群,根据用户的自定义业务逻辑,对海量数据进行分布式处理,Hadoop的核心组件有:
-
HDFS(分布式文件系统)
-
YARN(运算资源调度系统)
-
MAPREDUCE(分布式运算编程框架)
广义: Hadoop通常是指一个更广泛的概念 -> Hadoop生态圈
<font color=DarkGoldenRod>3、Hadoop产生背景</font>
① Hadoop最早起源于Nutch。Nutch的设计目标是构建一个大型的全网搜索引擎,包括网页抓取、索引、查询等功能,但随着抓取网页数量的增加,遇到了严重的可扩展性问题——如何解决数十亿网页的存储和索引问题。
② 2003年、2004年谷歌发表的两篇论文为该问题提供了可行的解决方案。
1. 分布式文件系统(GFS),可用于处理海量网页的存储
2. 分布式计算框架MAPREDUCE,可用于处理海量网页的索引计算问题。
③ Nutch的开发人员完成了相应的开源实现HDFS和MAPREDUCE,并从Nutch中剥离成为独立项目Hadoop,到2008年1月,Hadoop成为Apache顶级项目,迎来了它的快速发展期。
<font color=DarkGoldenRod>4、Hadoop生态系统</font>
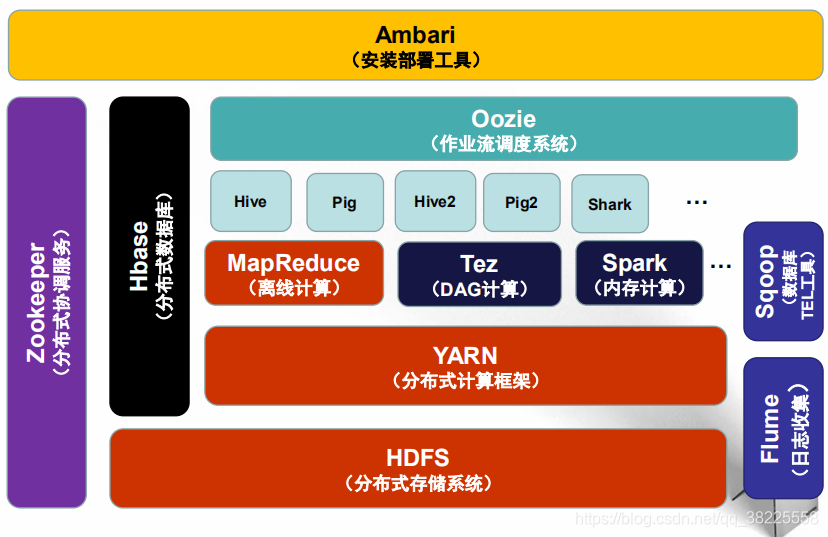
重点组件:
<font color=DeepPink>HDFS:分布式文件系统</font>
<font color=DeepPink>YARN:资源管理平台</font>
<font color=DeepPink>MAPREDUCE:分布式运算程序开发框架</font>
<font color=DeepPink>HIVE:基于大数据技术(文件系统+运算框架)的SQL数据仓库工具</font>
HBASE:基于HADOOP的分布式海量数据库
<font color=DeepPink>ZOOKEEPER:分布式协调服务基础组件</font>
Mahout:基于mapreduce/spark/flink等分布式运算框架的机器学习算法库
Oozie/azkaban:工作流调度框架
Sqoop:数据导入导出工具
Flume:日志数据采集框架
<font color=DarkGoldenRod>5、Hadoop发行版介绍(开源版)</font>
-
Apache Hadoop 推荐使用最新的2.x.x版本
下载地址: http://hadoop.apache.org/releases.html
SVN: http://svn.apache.org/repos/asf/hadoop/common/branches/
-
CDH(Cloudera Distributed Hadoop)
推荐使用最新的CDH5版本,比如CDH5.0.0
-
HDP(Hortonworks Data Platform)
推荐使用最新的HDP 2.x版本,比如HDP 2.1版本
以后工作中最好选择公司发行版(CDH或HDP),我们学习的话使用原生版本即可(Apache Hadoop)
<font color=DarkGoldenRod>6、使用场景</font>
-
Hadoop应用于数据服务基础平台建设

-
Hadoop用于用户画像
-
Hadoop用于网站点击流日志数据挖掘
金融行业: 个人征信分析
证券行业: 投资模型分析
交通行业: 车辆、路况监控分析
电信行业:用户上网行为分析
<font color=DarkGoldenRod>7、总结</font>
Hadoop广义上讲是Hadoop生态圈,包括了基础HDFS,Yarn,MapReduce(自带计算框架),还有一些辅助工具(Flume,azkaban,sqoop等)。注意在大数据领域除了hadoop以外还有两个比较重要的计算框架storm,spark等,它不属于hadoop广义生态圈
<font color=Cyan>二、HDFS概述</font>
<font color=DarkGoldenRod>1、HDFS是什么?</font>
全称Hadoop Distributed File System,叫做hadoop的分布式文件系统,源自于Google的GFS论文
发表于2003年10月,HDFS是GFS克隆版。提供了 高可靠性、高扩展性和高吞吐率的数据存储服务。为各类分布式运算框架(如:mapreduce,spark,tez,……)提供数据存储服务。
<font color=DarkGoldenRod>2、架构</font>
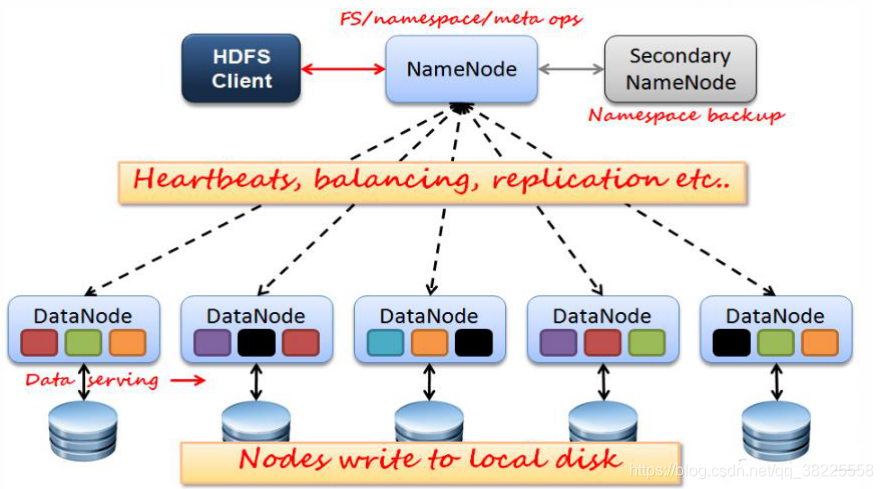
-
HDFS中的文件在物理上是分块存储(block),块的大小可以通过配置参数( dfs.blocksize)来规定,默认大小在hadoop2.x版本中是128M,老版本中是64M
-
HDFS文件系统会给客户端提供一个统一的抽象目录树,客户端通过路径来访问文件,形如:hdfs://namenode:port/dir-a/dir-b/dir-c/file.data
-
目录结构及文件分块位置信息(元数据)的管理由namenode节点承担 ——namenode是HDFS集群主节点,负责维护整个hdfs文件系统的目录树,以及每一个路径(文件)所对应的block块信息(block的id,及所在的datanode服务器)
-
文件的各个block的存储管理由datanode节点承担 —- datanode是HDFS集群从节点,每一个block都可以在多个datanode上存储多个副本(副本数量也可以通过参数设置dfs.replication,默认是3)
-
HDFS是设计成适应一次写入,多次读出的场景,且不支持文件的修改
<font color=DarkGoldenRod>3、优缺点</font>
优点:
- 高容错性
-
数据自动保存多个副本
-
副本丢失后,自动恢复
- 适合批处理
-
移动计算而非数据
-
数据位置暴露给计算框
- 适合大数据处理
-
GB 、TB 、甚至PB 级数据
-
- 百万规模以上的文件数量 • 10K+ 节点
- 可构建在廉价机器上
-
通过多副本提高可靠性
-
提供了容错和恢复
缺点:
- 低延迟数据访问
-
比如毫秒级
-
低延迟与高吞吐率
- 小文件存取
-
占用NameNode 大量内存
-
寻道时间超过读取时间
- 并发写入、文件随机修改
-
一个文件只能有一个写者
-
仅支持append
<font color=Cyan>三、Hadoop伪分布式安装</font>
伪分布式:一台主机安装多种节点(我们学习的话只有一个电脑,所以进行伪分布式安装)
安装完全分布式:NN Activie,NN Secodard,多个DataNode
要求:安装在linux环境下
<font color=DarkGoldenRod>1、Hadoop安装前准备</font>
-
克隆一个虚拟机,ip自动获取
vi /etc/udev/rules.d/70-persistent-net.rules 把原来的网卡项删掉,再把新的网卡名字改成eth0,保存 执行:start_udev vi /etc/sysconfig/network-scripts.sh/ifcfg-eth0 把HWADDR项里的MAC地址照着上面的文件改对,或者直接注释掉 重启网络:service network restart 或者重启主机:reboot -
关闭防火墙和SElinux
service iptables status service iptables stop chkconfig iptables off 永久关闭 vi /etc/sysconfig/selinux 设置为disabled -
设置hostname
hostname hadoop-yarn.zhengqing.com -
安装java
tar -zxvf mv 移动位置 vi /etc/profile export JAVA_HOME=/usr/local/jdk1.7 export PATH=$PATH:$JAVA_HOME/bin 验证: reboot java -version
<font color=DarkGoldenRod>2、Hadoop安装与配置</font>
tar -zxvf hadoop*tar.gz
为了解决警告,可以直接下载源码自己编译.但是这个过程比较复杂.
配置:
1、hadoop-env.sh
export JAVA_HOME=/opt/modules/jdk1.6.0_45
2、yarn-env.sh
export JAVA_HOME=/opt/modules/jdk1.6.0_45
3、mapred-env.sh
export JAVA_HOME=/opt/modules/jdk1.6.0_45
4、core-site.xml
<property>
<name>fs.default.name</name>
<value>hdfs://hadoop-yarn.dragon.org:8020</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/modules/hadoop-2.2.0/data/tmp</value>
</property>
5、hdfs-site.xml
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
6、yarn-site.xml
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
7、mapred-site.xml
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<font color=DarkGoldenRod>3、启动hdfs</font>
修改hostname
core-site.xml里面保持一致 hostname ...
DataNode NameNode SecendardNameNode
* NameNode 格式化
bin/hdfs namenode -format 产生一个集群的ID
* 启动NameNode
sbin/hadoop-daemon.sh start namenode
* 启动DataNode
sbin/hadoop-daemon.sh start datanode
* 启动SecondaryNameNode
sbin/hadoop-daemon.sh start secondarynamenode
jps
查看java进程 namenode secondarynamenode datanode
测试:
http://hadoop-yarn.zhengqing.com:50070
http://hadoop-yarn.zhengqing.com:50090
<font color=Cyan>四、HDFS的shell(命令行客户端)操作</font>
<font color=DarkGoldenRod>1、HDFS命令行客户端使用</font>
HDFS提供shell命令行客户端,使用方法如下:
可以使用如下两种形式:
hadoop fs -…
hdfs dfs -…
<font color=DarkGoldenRod>2、命令行客户端支持的命令参数</font>
[-appendToFile <localsrc> ... <dst>]
[-cat [-ignoreCrc] <src> ...]
[-checksum <src> ...]
[-chgrp [-R] GROUP PATH...]
[-chmod [-R] <MODE[,MODE]... | OCTALMODE> PATH...]
[-chown [-R] [OWNER][:[GROUP]] PATH...]
[-copyFromLocal [-f] [-p] <localsrc> ... <dst>]
[-copyToLocal [-p] [-ignoreCrc] [-crc] <src> ... <localdst>]
[-count [-q] <path> ...]
[-cp [-f] [-p] <src> ... <dst>]
[-createSnapshot <snapshotDir> [<snapshotName>]]
[-deleteSnapshot <snapshotDir> <snapshotName>]
[-df [-h] [<path> ...]]
[-du [-s] [-h] <path> ...]
[-expunge]
[-get [-p] [-ignoreCrc] [-crc] <src> ... <localdst>]
[-getfacl [-R] <path>]
[-getmerge [-nl] <src> <localdst>]
[-help [cmd ...]]
[-ls [-d] [-h] [-R] [<path> ...]]
[-mkdir [-p] <path> ...]
[-moveFromLocal <localsrc> ... <dst>]
[-moveToLocal <src> <localdst>]
[-mv <src> ... <dst>]
[-put [-f] [-p] <localsrc> ... <dst>]
[-renameSnapshot <snapshotDir> <oldName> <newName>]
[-rm [-f] [-r|-R] [-skipTrash] <src> ...]
[-rmdir [--ignore-fail-on-non-empty] <dir> ...]
[-setfacl [-R] [{-b|-k} {-m|-x <acl_spec>} <path>]|[--set <acl_spec> <path>]]
[-setrep [-R] [-w] <rep> <path> ...]
[-stat [format] <path> ...]
[-tail [-f] <file>]
[-test -[defsz] <path>]
[-text [-ignoreCrc] <src> ...]
[-touchz <path> ...]
[-usage [cmd ...]]
<font color=DarkGoldenRod>3、常用命令参数介绍</font>
-help
功能:输出这个命令参数手册
-ls
功能:显示目录信息
示例: hadoop fs -ls hdfs://hadoop-server01:9000/
备注:这些参数中,所有的hdfs路径都可以简写
-->hadoop fs -ls / 等同于上一条命令的效果
-mkdir
功能:在hdfs上创建目录
示例:hadoop fs -mkdir -p /aaa/bbb/cc/dd
-moveFromLocal
功能:从本地剪切粘贴到hdfs
示例:hadoop fs - moveFromLocal /home/hadoop/a.txt /aaa/bbb/cc/dd
-moveToLocal
功能:从hdfs剪切粘贴到本地
示例:hadoop fs - moveToLocal /aaa/bbb/cc/dd /home/hadoop/a.txt
--appendToFile
功能:追加一个文件到已经存在的文件末尾
示例:hadoop fs -appendToFile ./hello.txt hdfs://hadoop-server01:9000/hello.txt
可以简写为:
Hadoop fs -appendToFile ./hello.txt /hello.txt
-cat
功能:显示文件内容
示例:hadoop fs -cat /hello.txt
-tail
功能:显示一个文件的末尾
示例:hadoop fs -tail /weblog/access_log.1
-text
功能:以字符形式打印一个文件的内容
示例:hadoop fs -text /weblog/access_log.1
-chgrp
-chmod
-chown
功能:linux文件系统中的用法一样,对文件所属权限
示例:
hadoop fs -chmod 666 /hello.txt
hadoop fs -chown someuser:somegrp /hello.txt
-copyFromLocal
功能:从本地文件系统中拷贝文件到hdfs路径去
示例:hadoop fs -copyFromLocal ./jdk.tar.gz /aaa/
-copyToLocal
功能:从hdfs拷贝到本地
示例:hadoop fs -copyToLocal /aaa/jdk.tar.gz
-cp
功能:从hdfs的一个路径拷贝hdfs的另一个路径
示例: hadoop fs -cp /aaa/jdk.tar.gz /bbb/jdk.tar.gz.2
-mv
功能:在hdfs目录中移动文件
示例: hadoop fs -mv /aaa/jdk.tar.gz /
-get
功能:等同于copyToLocal,就是从hdfs下载文件到本地
示例:hadoop fs -get /aaa/jdk.tar.gz
-
功能:合并下载多个文件
示例:比getmerge 如hdfs的目录 /aaa/下有多个文件:log.1, log.2,log.3,...
hadoop fs -getmerge /aaa/log.* ./log.sum
-put
功能:等同于copyFromLocal
示例:hadoop fs -put /aaa/jdk.tar.gz /bbb/jdk.tar.gz.2
-rm
功能:删除文件或文件夹
示例:hadoop fs -rm -r /aaa/bbb/
-rmdir
功能:删除空目录
示例:hadoop fs -rmdir /aaa/bbb/ccc
-df
功能:统计文件系统的可用空间信息
示例:hadoop fs -df -h /
-du
功能:统计文件夹的大小信息
示例:
hadoop fs -du -s -h /aaa/*
-count
功能:统计一个指定目录下的文件节点数量
示例:hadoop fs -count /aaa/
-setrep
功能:设置hdfs中文件的副本数量
示例:hadoop fs -setrep 3 /aaa/jdk.tar.gz
<font color=Cyan>五、HDFS的Java操作</font>
hdfs在生产应用中主要是客户端的开发,其核心步骤是从hdfs提供的api中构造一个HDFS的访问客户端对象,然后通过该客户端对象操作(增删改查)HDFS上的文件
<font color=DarkGoldenRod>1、搭建开发环境</font>
① 引入依赖
注:如需手动引入jar包,hdfs的jar包—-hadoop的安装目录的share下
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.6.5</version>
</dependency>
public static void main(String[] args) throws IOException {
//创建配置对象并设置hdfs访问路径
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://hadoop-yarn.zhengqing.com:8020");
//伪造身份,必须放到获取文件系统前面
System.setProperty("HADOOP_USER_NAME","root");
//通过问卷系统进行访问
FileSystem fs = FileSystem.get(conf);
//本地拷贝到hdfs Permission denied: user=Administrator, access=WRITE, inode="/data01":root:supergroup:drwxr-xr-x
//fs.copyFromLocalFile(new Path( "G://dblog.sql"),new Path("/data01"));
//拷贝到本地
fs.copyToLocalFile(new Path("/data01/dblog.sql"),new Path("c://"));
//递归列表根路径下面所有的文件
RemoteIterator<LocatedFileStatus> iterator = fs.listFiles(new Path("/"), true);
while (iterator.hasNext()) {
LocatedFileStatus next = iterator.next();
System.out.println(next.getPath());
}
fs.close();
}
② window下开发的说明
建议在linux下进行hadoop应用的开发,不会存在兼容性问题。如在window上做客户端应用开发,需要设置以下环境:
-
下载windows平台下编译的hadoop安装包解压一份到windows的任意一个目录下
-
在window系统中配置HADOOP_HOME指向你解压的安装包目录
-
在windows系统的path变量中加入HADOOP_HOME的bin目录
<font color=DarkGoldenRod>2、获取api中的客户端对象</font>
在java中操作hdfs,首先要获得一个客户端实例
Configuration conf = new Configuration()
FileSystem fs = FileSystem.get(conf)
而我们的操作目标是HDFS,所以获取到的fs对象应该是DistributedFileSystem的实例;
get方法是从何处判断具体实例化那种客户端类呢?
- 从conf中的一个参数 fs.defaultFS的配置值判断;
如果我们的代码中没有指定fs.defaultFS,并且工程classpath下也没有给定相应的配置,conf中的默认值就来自于hadoop的jar包中的core-default.xml,默认值为: file:///,则获取的将不是一个DistributedFileSystem的实例,而是一个本地文件系统的客户端对象
<font color=DarkGoldenRod>3、DistributedFileSystem实例对象所具备的方法</font>
<font color=DarkGoldenRod>4、HDFS客户端操作数据代码示例</font>
文件的增删改查:
public class HdfsClient {
FileSystem fs = null;
@Before
public void init() throws Exception {
// 构造一个配置参数对象,设置一个参数:我们要访问的hdfs的URI
// 从而FileSystem.get()方法就知道应该是去构造一个访问hdfs文件系统的客户端,以及hdfs的访问地址
// new Configuration();的时候,它就会去加载jar包中的hdfs-default.xml
// 然后再加载classpath下的hdfs-site.xml
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://hdp-node01:9000");
/**
* 参数优先级: 1、客户端代码中设置的值 2、classpath下的用户自定义配置文件 3、然后是服务器的默认配置
*/
conf.set("dfs.replication", "3");
// 获取一个hdfs的访问客户端,根据参数,这个实例应该是DistributedFileSystem的实例
// fs = FileSystem.get(conf);
// 如果这样去获取,那conf里面就可以不要配"fs.defaultFS"参数,而且,这个客户端的身份标识已经是hadoop用户
fs = FileSystem.get(new URI("hdfs://hdp-node01:9000"), conf, "hadoop");
}
/**
* 往hdfs上传文件
* @throws Exception
*/
@Test
public void testAddFileToHdfs() throws Exception {
// 要上传的文件所在的本地路径
Path src = new Path("g:/redis-recommend.zip");
// 要上传到hdfs的目标路径
Path dst = new Path("/aaa");
fs.copyFromLocalFile(src, dst);
fs.close();
}
/**
* 从hdfs中复制文件到本地文件系统
* @throws IOException
* @throws IllegalArgumentException
*/
@Test
public void testDownloadFileToLocal() throws IllegalArgumentException, IOException {
fs.copyToLocalFile(new Path("/jdk-7u65-linux-i586.tar.gz"), new Path("d:/"));
fs.close();
}
@Test
public void testMkdirAndDeleteAndRename() throws IllegalArgumentException, IOException {
// 创建目录
fs.mkdirs(new Path("/a1/b1/c1"));
// 删除文件夹 ,如果是非空文件夹,参数2必须给值true
fs.delete(new Path("/aaa"), true);
// 重命名文件或文件夹
fs.rename(new Path("/a1"), new Path("/a2"));
}
/**
* 查看目录信息,只显示文件
* @throws IOException
* @throws IllegalArgumentException
* @throws FileNotFoundException
*/
@Test
public void testListFiles() throws FileNotFoundException, IllegalArgumentException, IOException {
// 思考:为什么返回迭代器,而不是List之类的容器
RemoteIterator<LocatedFileStatus> listFiles = fs.listFiles(new Path("/"), true);
while (listFiles.hasNext()) {
LocatedFileStatus fileStatus = listFiles.next();
System.out.println(fileStatus.getPath().getName());
System.out.println(fileStatus.getBlockSize());
System.out.println(fileStatus.getPermission());
System.out.println(fileStatus.getLen());
BlockLocation[] blockLocations = fileStatus.getBlockLocations();
for (BlockLocation bl : blockLocations) {
System.out.println("block-length:" + bl.getLength() + "--" + "block-offset:" + bl.getOffset());
String[] hosts = bl.getHosts();
for (String host : hosts) {
System.out.println(host);
}
}
System.out.println("--------------为angelababy打印的分割线--------------");
}
}
/**
* 查看文件及文件夹信息
* @throws IOException
* @throws IllegalArgumentException
* @throws FileNotFoundException
*/
@Test
public void testListAll() throws FileNotFoundException, IllegalArgumentException, IOException {
FileStatus[] listStatus = fs.listStatus(new Path("/"));
String flag = "d-- ";
for (FileStatus fstatus : listStatus) {
if (fstatus.isFile()) flag = "f-- ";
System.out.println(flag + fstatus.getPath().getName());
}
}
}
<font color=DarkGoldenRod>5、通过流的方式访问hdfs</font>
/**
* 相对那些封装好的方法而言的更底层一些的操作方式
* 上层那些mapreduce spark等运算框架,去hdfs中获取数据的时候,就是调的这种底层的api
* @author 郑清
*/
public class StreamAccess {
FileSystem fs = null;
@Before
public void init() throws Exception {
Configuration conf = new Configuration();
fs = FileSystem.get(new URI("hdfs://hdp-node01:9000"), conf, "hadoop");
}
/**
* 通过流的方式上传文件到hdfs
* @throws Exception
*/
@Test
public void testUpload() throws Exception {
FSDataOutputStream outputStream = fs.create(new Path("/angelababy.love"), true);
FileInputStream inputStream = new FileInputStream("c:/angelababy.love");
IOUtils.copy(inputStream, outputStream);
}
@Test
public void testDownLoadFileToLocal() throws IllegalArgumentException, IOException{
//先获取一个文件的输入流----针对hdfs上的
FSDataInputStream in = fs.open(new Path("/jdk-7u65-linux-i586.tar.gz"));
//再构造一个文件的输出流----针对本地的
FileOutputStream out = new FileOutputStream(new File("c:/jdk.tar.gz"));
//再将输入流中数据传输到输出流
IOUtils.copyBytes(in, out, 4096);
}
/**
* hdfs支持随机定位进行文件读取,而且可以方便地读取指定长度
* 用于上层分布式运算框架并发处理数据
* @throws IllegalArgumentException
* @throws IOException
*/
@Test
public void testRandomAccess() throws IllegalArgumentException, IOException{
//先获取一个文件的输入流----针对hdfs上的
FSDataInputStream in = fs.open(new Path("/iloveyou.txt"));
//可以将流的起始偏移量进行自定义
in.seek(22);
//再构造一个文件的输出流----针对本地的
FileOutputStream out = new FileOutputStream(new File("c:/iloveyou.line.2.txt"));
IOUtils.copyBytes(in,out,19L,true);
}
/**
* 显示hdfs上文件的内容
* @throws IOException
* @throws IllegalArgumentException
*/
@Test
public void testCat() throws IllegalArgumentException, IOException{
FSDataInputStream in = fs.open(new Path("/iloveyou.txt"));
IOUtils.copyBytes(in, System.out, 1024);
}
}
<font color=DarkGoldenRod>6、场景编程</font>
在mapreduce 、spark等运算框架中,有一个核心思想就是将运算移往数据,或者说,就是要在并发计算中尽可能让运算本地化,这就需要获取数据所在位置的信息并进行相应范围读取
以下模拟实现:获取一个文件的所有block位置信息,然后读取指定block中的内容
@Test
public void testCat() throws IllegalArgumentException, IOException{
FSDataInputStream in = fs.open(new Path("/weblog/input/access.log.10"));
//拿到文件信息
FileStatus[] listStatus = fs.listStatus(new Path("/weblog/input/access.log.10"));
//获取这个文件的所有block的信息
BlockLocation[] fileBlockLocations = fs.getFileBlockLocations(listStatus[0], 0L, listStatus[0].getLen());
//第一个block的长度
long length = fileBlockLocations[0].getLength();
//第一个block的起始偏移量
long offset = fileBlockLocations[0].getOffset();
System.out.println(length);
System.out.println(offset);
//获取第一个block写入输出流
// IOUtils.copyBytes(in, System.out, (int)length);
byte[] b = new byte[4096];
FileOutputStream os = new FileOutputStream(new File("d:/block0"));
while(in.read(offset, b, 0, 4096)!=-1){
os.write(b);
offset += 4096;
if(offset>=length) return;
};
os.flush();
os.close();
in.close();
}
